
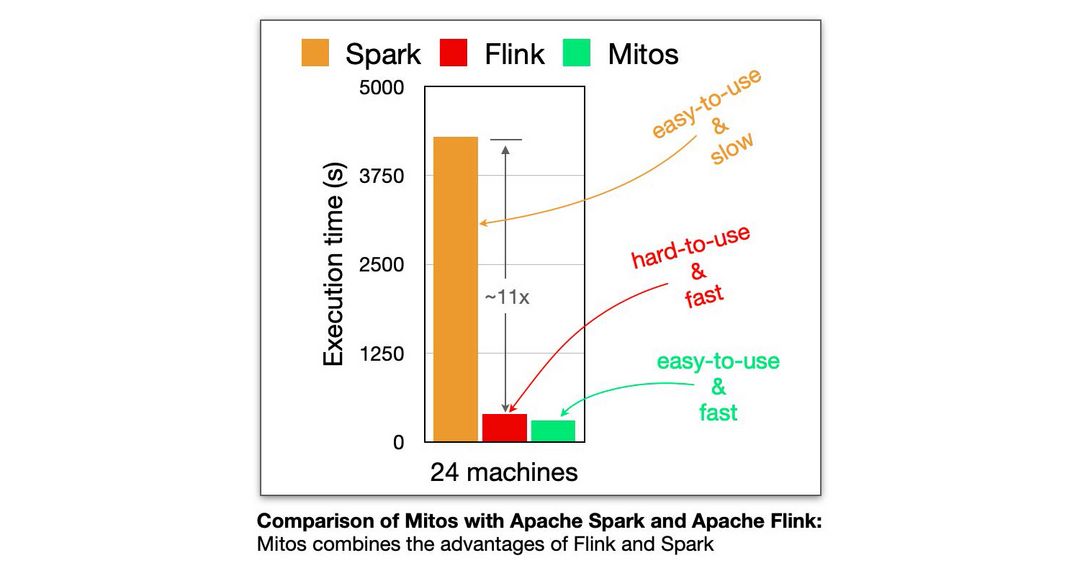
In modern data analytics, companies often want to analyze large datasets. For example, a company might want to analyze its entire network of user interactions in order to better understand how its products are used. Scaling data analysis to large datasets is a widespread need in many different contexts. Modern dataflow systems, such as Apache Flink and Apache Spark are widely used to accomplish that need. But the kind of algorithms that are used for data analysis are getting more and more complex. Complex algorithms are often iterative in nature, meaning that they gradually refine the results by repeated execution of a computation. A well-known example is the PageRank algorithm, which is used for ranking the importance of nodes in a network, for example ranking websites in Google search results. Both dataflow systems Apache Flink and Apache Spark have weaknesses when implementing iterative algorithms: they are either hard to use, or have suboptimal performance.
This paper introduces a new system, which combines an easy-to-use language with efficient execution. It is able to keep the language simple by relying on techniques from the programming language research literature, in addition to the database and distributed systems research literature, which earlier systems relied on. The simpler language makes it easy for users to run advanced analytics on large datasets. This is important for data scientists, who can then concentrate on the analytics instead of needing to become experts on the internal workings of the systems.
The annual IEEE International Conference on Data Engineering (ICDE) is the flagship IEEE conference addressing research issues in designing, building, managing, and evaluating advanced data-intensive systems and applications. For over three decades, IEEE ICDE has been a leading forum for researchers, practitioners, developers, and users to explore cutting-edge ideas and to exchange techniques, tools, and experiences.