
The workshop was part of an event series about language data and data repositories and targeted participants from Kenya, who are currently collecting language tools for Swahili, such as universities whose data collection activities for Swahili are supported by the Lacuna Fund as well as representatives from Mozilla, the iLab of Strathmore University and the Microsoft Africa Research Institute. The workshop series aims to support the different parties in coordinating language data, to foster an interactive exchange of knowledge and to avoid a duplication of effort.
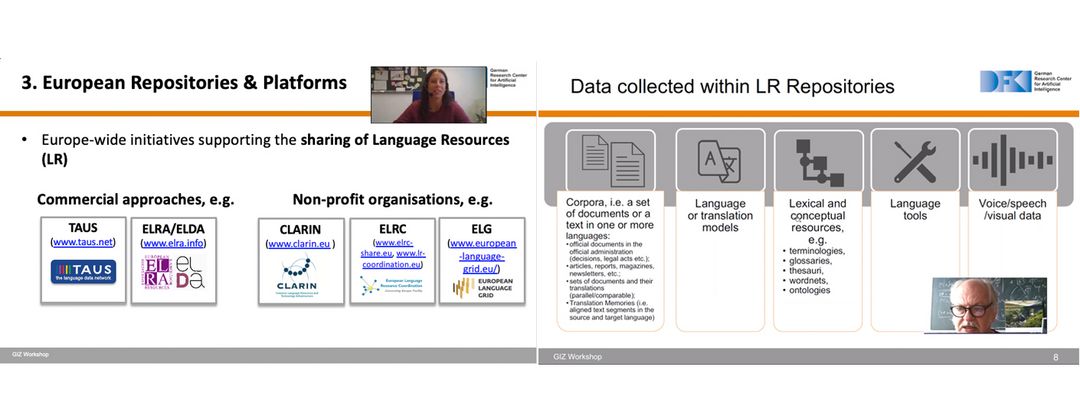
At the workshop on 28 July, Andrea Lösch (Leader of the MLT group “Data and Resources”, short D&R Group) and Thierry Declerck (Senior Consultant and Senior Researcher at DFKI) put a spotlight on the question „Sharing Language Data – but how?”. Using best practice examples, they demonstrated how language data can be made retrievable and openly accessible to a broad community. Andrea Lösch first presented a number of European initiatives which support the sharing language data, including commercial approaches like ELRA/ELDA or TAUS but also non-profit organisations like the European Language Resource Coordination (ELRC) or CLARIN. Besides the strengths and weaknesses of each solution, the audience also gained first insights into the requirements and resources needed to develop a comparable repository for Swahili.
Thierry Declerck followed up on this by presenting methods for data processing and data validation and shared useful hints about where to find and collect language data for Swahili. It was emphasised that both the legal validation, i.e. using and sharing language data in compliance with the defined license rights, as well as the technical validation, i.e. ensuring a certain level of data quality are critical to the usability of language resources and thus to the development of a repository. For this, a mix of manual and automatic evaluation will be required. Thanks to the interactive participation in the workshop, one question that came up was how to track the use and usefulness of the language resources provided through the repository. Using the example of the “ELRC SHARE” Repository, Andrea Lösch explained that there are ways to integrate tracking functions that show how often the data sets are being accessed and from which countries the requests come, which in turn can also provide useful information about the use and relevance of the data set.
By putting a spotlight on European best practices coupled with technical know-how on data processing and sharing, participants moved one step closer to answering the question “Sharing language data – but how?”. A live survey conducted by the participants provided a first summary of the concrete requirements for a language data repository for Swahili. The new insights will now be applied to the conditions of the Kenyan participants – and here, too, the MLT group will be on hand to provide advice. For more information on this and related topics, please visit the Website of the D&R Group.
Website GIZ
https://www.giz.de/de/html/index.html