
Der Workshop war Teil einer Veranstaltungsreihe mit Fokus auf Sprachdaten und Daten-Repositories und richtet sich an Teilnehmer aus Kenia, die Sprachtechnologien für Swahili sammeln – darunter Universitäten, die vom Lacuna Fund gefördert werden, um Daten für Swahili zu sammeln und weitere Akteure wie Mozilla, das iLab der Strathmore University und das Microsoft Africa Research Institute. Das Ziel der Workshopreihe besteht darin, die Teilnehmer bei der Koordinierung von Sprachdaten zu unterstützen, einen interaktiven Wissensaustausch zu fördern und Duplikation zu verhindern.
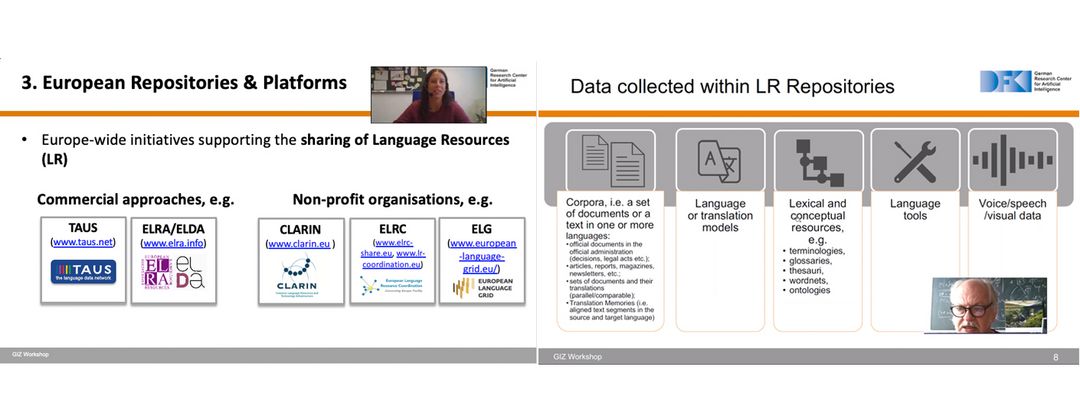
Bei der Onlineveranstaltung am 28. Juli befassten sich Andrea Lösch (Leiterin der MLT-Gruppe „Daten und Ressourcen“, kurz „D&R-Gruppe“) und Thierry Declerck (Senior Consultant und Senior Researcher am DFKI) mit dem Thema „Sharing Language Data – but how?“ und zeigten anhand von Best Practice Beispielen, wie Sprachdaten auffindbar und offen zugänglich gemacht werden können. Dabei stellte Andrea Lösch zunächst verschiedene europäische Initiativen zur Bereitstellung von Sprachdaten vor, darunter kommerzielle Ansätze wie ELRA/ELDA oder TAUS, aber auch Non-Profit-Organisationen wie die European Language Resource Coordination (ELRC) oder CLARIN. Neben den Vor- und Nachteilen der jeweiligen Lösungen konnten die Teilnehmer auch erste Einblicke in die Voraussetzungen und benötigten Ressourcen zur Entwicklung vergleichbarer Repositories für Swahili gewinnen.
Im Anschluss widmete sich Thierry Declerck der Datenverarbeitung und -validierung und zeigte Möglichkeiten zur Sprachdatensammlung für Swahili auf. Dabei wurde betont, dass sowohl die rechtliche Validierung, d.h. das Nutzen und Teilen von Sprachdaten gemäß den angegebenen Lizenzrechten, als auch die technische Validierung, also das Sicherstellen einer angemessenen Datenqualität, maßgeblich für die Nutzbarkeit der Sprachdaten und somit für die Entwicklung von Repositories sind. Dafür sei eine Mischung aus manueller und automatisierter Evaluierung erforderlich. Durch die interaktive Teilhabe am Workshop kam unter anderem auch die Frage nach der Nachvollziehbarkeit von Verwendung und Nutzen der Sprachdaten in einem Repository auf. Am Beispiel des „ELRC SHARE“ Repository erklärte Andrea Lösch, dass Trackingfunktionen integriert werden können, die zeigen, wie häufig und in welchen Ländern auf die Datensätze zugegriffen wird, was wiederrum Aufschluss über die Nutzung und Relevanz der Daten geben kann.
Durch die Beleuchtung europäischer Best Practices gepaart mit der Vermittlung von technischem Knowhow zur Datenverarbeitung und -bereitstellung sind die Teilnehmer der Antwort zur Frage „Sprachdaten teilen – aber wie?“ einen Schritt nähergekommen. Eine erste Zusammenfassung der konkreten Anforderungen an ein Repository für Sprachdaten für Swahili lieferte eine live durchgeführte Umfrage unter den Teilnehmern. Im Rahmen eines Follow-ups sollen die neu gewonnenen Erkenntnisse nun auf die Gegebenheiten der kenianischen Akteure angewendet werden – auch hier wird ihnen die MLT-Gruppe beratend zur Seite stehen. Weitere Informationen zu diesem und verwandten Themen finden Sie auf der Webseite der D&R-Gruppe.
GIZ Webseite:
https://www.giz.de/de/html/index.html