
Der TU Berlin Master-Absolvent Alexander Kumaigorodski und seine Co-Autoren aus dem Forschungsbereich Intelligente Analytik für Massendaten (IAM) von Prof. Dr. Volker Markl am Deutschen Forschungszentrum für Künstliche Intelligenz (DFKI) und dem Fachgebiet Datenbanksysteme und Informationsmanagement (DIMA) der TU Berlin präsentieren einen neuen Ansatz, um das Laden und Verarbeiten von tabellarischen CSV-Daten um mehrere Größenordnungen zu beschleunigen.
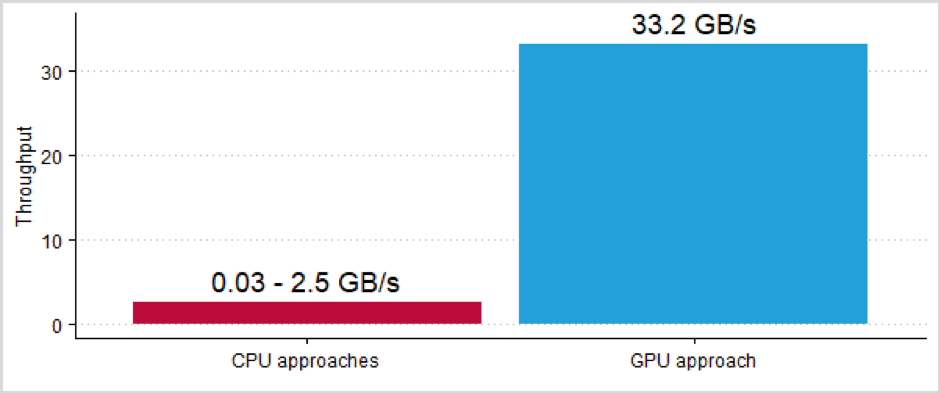
CSV ist ein sehr häufig verwendetes Format für den Austausch von strukturierten Daten. So veröffentlicht beispielsweise die Stadt Berlin ihre strukturierten Datensätze im CSV-Format im Berlin Open Data Portal. Solche Datensätze können in Datenbanken zur Datenanalyse importiert werden. Die Beschleunigung dieses Prozesses ermöglicht es den Anwendern, die zunehmende Datenmenge zu bewältigen und den Zeitaufwand für die Datenanalyse zu verringern. Jede neue Generation von Computernetzwerken und Speichermedien bietet höhere Bandbreiten und ermöglicht schnellere Lesezeiten. Bestehende Ansätze zum Laden und Verarbeiten mit Hauptprozessoren (CPU) können jedoch mit diesen Hardwaretechnologien nicht mithalten und drosseln die Ladezeiten unnötig.
Das in diesem Beitrag beschriebene Verfahren verwendet einen neuen Ansatz, bei dem die CSV-Daten stattdessen von Grafikprozessoren (GPU) gelesen und verarbeitet werden. Der Vorteil dieser Grafikprozessoren liegt vor allem in ihrer starken parallelen Rechenleistung und dem schnellen Speicherzugriff. Mit diesem Ansatz können neue Hardware-Technologien, wie z. B. NVLink 2.0 oder InfiniBand mit Remote Direct Memory Access (RDMA), voll ausgenutzt werden. Im Ergebnis können CSV-Daten direkt aus dem Hauptspeicher oder dem Netzwerk gelesen und mit mehreren Gigabyte pro Sekunde verarbeitet werden.
Die Transparenz der durchgeführten Tests und die unabhängige Bestätigung der Ergebnisse führten auch zur Verleihung des erstmals vergebenen BTW 2021 Reproducibility Badge. In der Data-Science-Community gewinnt die Reproduzierbarkeit von Forschungsergebnissen zunehmend an Bedeutung. Sie dient der Verifizierung von Ergebnissen sowie dem Vergleich mit bestehenden Arbeiten und ist damit ein wichtiger Aspekt der wissenschaftlichen Qualitätssicherung. Führende internationale Konferenzen haben diesem Thema daher bereits besondere Aufmerksamkeit gewidmet.
Um eine hohe Reproduzierbarkeit zu gewährleisten, stellten die Autoren dem Reproduzierbarkeitskomitee den Quellcode, zusätzliche Testdaten und eine Anleitung zur Ausführung der Benchmarks zur Verfügung. Die Ausführung der Tests wurde in einer Live-Sitzung demonstriert und konnte dann auch von einem Mitglied des Komitees erfolgreich repliziert werden. Mit der Reproducibility Badge wird vor allem die gute wissenschaftliche Praxis der Autoren gewürdigt.