
Das Paper mit dem Titel „Autoencoder for Synthetic to Real Generalization: From Simple to More Complex Scenes“ von Steve Dias Da Cruz, Prof. Didier Stricker, Dr. Bertram Taetz, und Thomas Stifter beschäftigt sich mit dem Trainieren auf ausschließlich synthetischen Daten und arbeitet lösungsorientiert heraus, welches Potenzial in dieser Herangehensweise hinsichtlich Kosteneffizienz und Sicherheit liegt.
Die ICPR ist die weltweit führende Konferenz für Mustererkennung, Computer Vision und Bildverarbeitung und fand vom 21. Bis 25. August 2022 in Montréal/ Québec statt.
Das Lernen auf synthetischen Daten und die Übertragung der daraus resultierenden Eigenschaften auf ihre realen Gegenstücke stellen eine wichtige Herausforderung dar, um Kosten einzusparen und die Sicherheit beim maschinellen Lernen maßgeblich zu erhöhen. Synthetische Daten werden durch einen Computeralgorithmus generiert. Anders als Originaldaten weisen sie keinen Personenbezug mehr auf. Dennoch werden mit den synthetischen Daten die Originaldatensätze gespiegelt, um verlässliche statistische Aussagen treffen zu können.
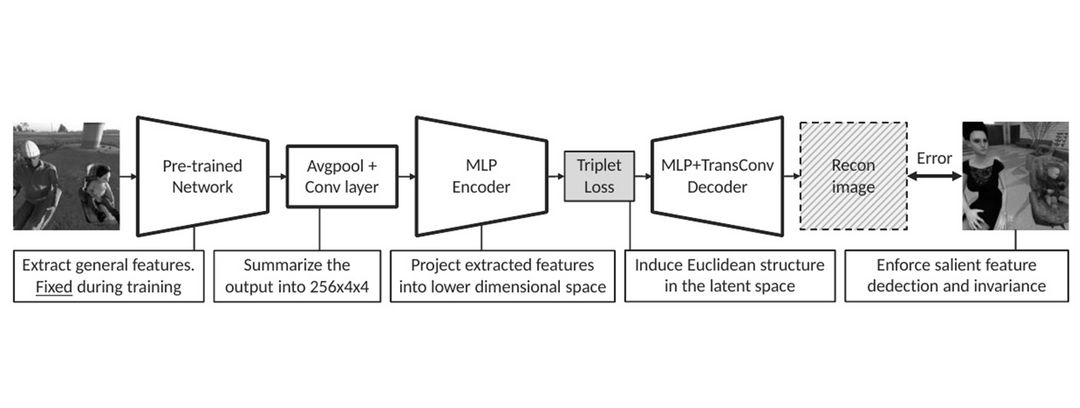
Nach dem Ansatz der DFKI-Wissenschaftler werden ausschließlich synthetische Bilder für das Training von Algorithmen verwendet. Zum einen erhöht dies die Generalisierbarkeit. Des Weiteren wird die Erhaltung der Bedeutung auf realen Datensätzen mit zunehmender visueller Komplexität verbessert. Sinngemäß wird eine neue Sampling-Technik vorgestellt, die semantisch wichtige Teile des Bildes abgleicht. Währenddessen werden die anderen Teile zufällig ausgewählt, was zu einer hervorstechenden Merkmalsextraktion und einer Vernachlässigung der unwichtigen Teile führt. Dies erleichtert die Verallgemeinerung auf reale Daten und zeigt außerdem, dass der Ansatz besser ist als fein abgestimmte Klassifizierungsmodelle.