
Projekt Luminous: Die nächste Stufe der erweiterten Realität
| Transfer-Stories | Anwendungsfelder | Lernen & Bildung | Smart Home & Assisted Living | Wissen & Business Intelligence | Autonome Systeme | Lernende Systeme | Mensch Maschine Interaktion | Sprache & Textverstehen | Virtual & Augmented Reality | Erweiterte Realität | Kaiserslautern | Pressemitteilung

An diesem Punkt kommt das System von LUMINOUS (Language Augmentation for Humanverse), entwickelt im Deutschen Forschungszentrum für Künstliche Intelligenz (DFKI), ins Spiel. Die Technologie sammelt die unzähligen Eindrücke, interpretiert sie und kann mittels generativen und multimodalen Sprachmodellen (MLLM) eine adäquate Handlung vorschlagen.

"Durch die von uns entwickelte Technologie werden virtuelle Welten intelligenter. Die intuitive Interaktion (per Text) mit dem System und automatische Generierung komplexer Verhaltensweisen und Abläufe durch „generative KI“ oder sogenannte "Multi-Modal Large Language Models" ermöglichen uns diese nicht nur zu erleben, sondern auch zu testen. Um das zu erreichen, arbeiten wir in LUMINOUS parallel an mehreren Ansätzen wie automatische Code-Generierung, dem schnellen Einpflegen von neuen Daten und weiteren Lösungen."
System beobachtet, interpretiert – und gibt Handlungsempfehlungen
Im neuen Projekt LUMINOUS arbeitet das DFKI an Erweiterter Realität (XR) Systemen der nächsten Generation. So sollen sich MLLM in Zukunft den bisherigen technischen Erweiterungen unserer visuell wahrgenommenen Realität, wie etwa in Form von Texten, Animationen oder der Einblendung von virtuellen Objekten, anschließen und die Interaktion mit Erweiterter Realität (XR) Technologie neu definieren.
Wie das in der Praxis aussehen kann, erklärt Muhammad Zeshan Afzal, Forscher aus dem Bereich Erweiterte Realität am Deutschen Forschungszentrum für Künstliche Intelligenz (DFKI), anhand eines Szenarios:
„Ein Feuer entsteht in einem Raum. Unser System ermittelt in diesem Fall zunächst, wo sich die Person – welche mit unserer Technologie ausgestattet ist – gerade befindet. Dann werden relevante Daten aus ihrem unmittelbaren Umfeld gesammelt, wie beispielsweise die Anwesenheit eines Feuerlöschers oder eines Notausgangs, um diese wiederum an das generative und multimodale Sprachmodell weiterzugeben. Dieses ermittelt dann eine passende Handlungsempfehlung, wie beispielsweise den Löschvorgang mittels Feuerlöscher einzuleiten, Fenster zu schließen oder sich in Sicherheit zu bringen.“
 © ai generated
© ai generated © ai generated
© ai generated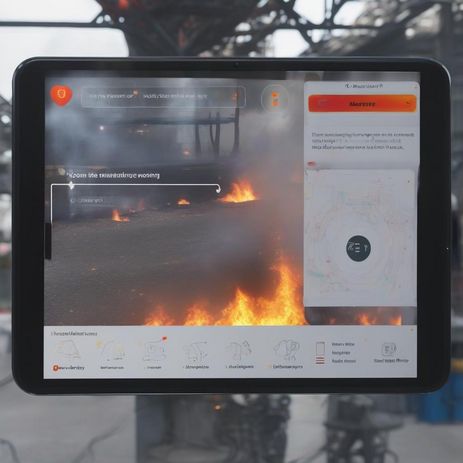 © ai generated
© ai generatedVon Beschreibungen lernen schafft Flexibilität
Bisher waren Forschungs- und Entwicklungsbestrebungen weitestgehend auf die räumliche Nachverfolgung der Nutzer und ihrer Umgebung beschränkt. Die Folge: Sehr spezifische, eingeschränkte und nicht generalisierbare Repräsentationen, sowie vordefinierte grafische Visualisierungen und Animationen. Das soll sich durch „Language Augmentation for Humanverse“ künftig ändern.
Um das zu erreichen, entwickeln die Forscherinnen und Forscher am DFKI eine Plattform mit Sprachunterstützung, die sich an individuelle, nicht vordefinierte Nutzerbedürfnisse und bisher unbekannte Umgebungen der erweiterten Realität anpasst. Das anpassungsfähige Konzept entstammt dem Zero-Shot Learning (ZSL), einem KI-System, das darauf trainiert ist, Objekte und Szenarien zu erkennen und zu kategorisieren – ohne exemplarisches Referenzmaterial vorab gesehen zu haben. In der Umsetzung soll LUMINOUS mit seiner Datenbank von Bildbeschreibungen ein flexibles Bild- und Textvokabular aufbauen, das es ermöglicht, auch unbekannte Objekte oder Szenen in Bildern und Videos zu erkennen.
Interaktive Unterstützung in Echtzeit
 © ai generated
© ai generated„Aktuell untersuchen wir mögliche Anwendungen für die Alltagsbetreuung von erkrankten Menschen, Implementierung von Trainingsprogrammen, Leistungsüberwachung und Motivation“, sagt Zeshan Afzal.
Das LLM aus dem Projekt LUMINOUS soll als eine Art Übersetzer dazu in der Lage sein, Alltagstätigkeiten auf Befehl zu beschreiben und mittels Sprachinterface oder Avatar an die NutzerInnen auszuspielen. Durch die so bereitgestellten visuellen Hilfestellungen und Handlungsempfehlungen werden dann Alltagsaktivitäten in Echtzeit unterstützend begleitet.
LUMINOUS in der Praxis
 © ai generated
© ai generatedDie Ergebnisse des Projekts werden in drei Pilotprojekten getestet, die sich auf Neurorehabilitation (Unterstützung von Schlaganfallpatienten mit Sprachstörungen), immersives Sicherheitstraining am Arbeitsplatz und die Überprüfung von 3D-Architekturentwürfen konzentrieren.
Im Fall der Neurorehabilitation von Schlaganfallpatienten mit schweren Kommunikationsdefiziten (Aphasie) unterstützen realitätsnahe virtuelle Charaktere (Avatare) die Gesprächsinitiierung durch bilddirektionale Modelle. Diese basieren auf natürlicher Sprache und ermöglichen eine Generalisierung auf weitere Aktivitäten des täglichen Lebens. Objekte in der Szene (einschließlich Personen) werden mithilfe von Eye-Tracking und Objekterkennungsalgorithmen in Echtzeit erkannt.
Die Patienten können dann den Avatar bzw. das MLLM auffordern, entweder den Namen des Objekts, das Ganze zu produzierende Wort, das erste Phonem oder den ersten Sprachlaut zu artikulieren.
 © ai generated
© ai generatedZur Verwendung der Sprachmodelle in der für sie einzigartigen Umgebung des Patienten, durchlaufen die Patienten ein personalisiertes und intensives XR-gestütztes Training. Dabei erfasst das Projekt LUMINOUS die Bewegungen und den Stil des menschlichen Trainers mit einer minimalen Anzahl von Sensoren, um die Modellierung und Instanziierung von dreidimensionalen Avataren zu ermöglichen. Ziel ist es, nur kinematische Informationen zu verwenden, die ausschließlich aus dem Input des Headsets, der Position des Kopfes und der Hände während des Trainings abgeleitet werden.
Zukünftige Nutzer dieser neuen XR-Systeme werden in der Lage sein, nahtlos mit ihrer Umgebung zu interagieren, indem sie Sprachmodelle verwenden und gleichzeitig Zugang zu ständig aktualisierten globalen und domänenspezifischen Wissensquellen haben.
Auf diese Weise können neue XR-Technologien in Zukunft beispielsweise für Fernunterricht und -ausbildung, Unterhaltung oder Gesundheitsdienste eingesetzt werden. Durch die Hilfestellungen lernt LUMINOUS dazu und erweitert sein Wissen stetig – über die reinen Trainingsdaten hinaus. Indem Namen und Textbeschreibungen dem LLM zur Verfügung gestellt werden, kann dieses umgekehrt die Namen unbekannter Objekte aus Bildern generieren. Erkannte Bildmerkmale werden mit den entsprechenden Textbeschreibungen verknüpft.
Partners:
- German Research Centre for Artificial Intelligence GmbH (DFKI)
- Ludus Tech SL
- Mindesk Societa a Responsabilita Limita
- Fraunhofer Society for the Advancement of Applied Research
- Universidad del Pais Vasco/Euskal Herriko Universitatea
- Fundación Centro de Tecnologias de Interacción visual y Comunicaciones Vicomtech
- University College Dublin
- National University of Ireland
- Hypercliq IKE
- Ricoh International B.V. – Brach Office Germany
- MindMaze SA
- Centre Hospitalier Universitaire Vaudois
- University College London
The project is subsidised by the European Union. Project LUMINOUS (Language Augmentation for Humanverse) does in no way shape or form relate to the AI Language Model Luminous, developed by Aleph Alpha.
Kontakt:
Muhammad Zeshan Afzal
Researcher, DFKI
- Muhammad_Zeshan.Afzal@dfki.de
- Tel.: +49 631 20575 3494
Prof. Dr. Didier Stricker
Forschungsbereichsleiter "Erweiterte Realität", DFKI
- Didier.Stricker@dfki.de
- Tel.: +49 631 20575 3500